
In 1977, two years after the last helicopter lifted off the rooftop of the U.S. embassy in Saigon, a retired Army general, Douglas Kinnard, published a landmark survey called The War Managers that revealed the quagmire of quantification. A mere 2 percent of America’s generals considered the body count a valid way to measure progress. “A fake—totally worthless,” wrote one general in his comments. “Often blatant lies,” wrote another. “They were grossly exaggerated by many units primarily because of the incredible interest shown by people like McNamara,” said a third.
The use, abuse, and misuse of data by the U.S. military during the Vietnam War is a troubling lesson about the limitations of information as the world hurls toward the big-data era. The underlying data can be of poor quality. It can be biased. It can be misanalyzed or used misleadingly. And even more damning, data can fail to capture what it purports to quantify.
Posts in Category ‘Information Architecture’
I haven’t thought too deeply about this in what feels like a hundred years, but somehow the DIKW pyramid reared it’s head when talking to the kids about Youtube and all the fake crap on social media.
The real problem isn’t the DIKW’s hijacking of the word “knowledge” but its implication that knowledge derives from filtering information. It doesn’t. We can learn some facts by combing through databases. We can see some true correlations by running sophisticated algorithms over massive amounts of information. All that’s good.
But knowledge is not a result merely of filtering or algorithms. It results from a far more complex process that is social, goal-driven, contextual, and culturally-bound. We get to knowledge — especially “actionable” knowledge — by having desires and curiosity, through plotting and play, by being wrong more often than right, by talking with others and forming social bonds, by applying methods and then backing away from them, by calculation and serendipity, by rationality and intuition, by institutional processes and social roles. Most important in this regard, where the decisions are tough and knowledge is hard to come by, knowledge is not determined by information, for it is the knowing process that first decides which information is relevant, and how it is to be used.
Problems with the Data-Information-Knowledge-Wisdom Hierarchy
The index card was a product of the Enlightenment, conceived by one of its towering figures: Carl Linnaeus, the Swedish botanist, physician, and the father of modern taxonomy. But like all information systems, the index card had unexpected political implications, too: It helped set the stage for categorizing people, and for the prejudice and violence that comes along with such classification.
Card sorting
Before going to China I expanded my collection of books to include all kinds of less generalised design topics – just in case – Card Sorting by Donna Spencer was one of them. Living without instant Google search results resulted in all kinds of changes to how I worked and remembered. No need to remember I’ll just Google it later. Kudos to the local Chinese designers who grew up with the resources linked to by Baidu – it’s a desert of quality info there.
I haven’t done a proper card sort in many years, but at the time it was one of my favorite methods. For the audience I was working with it was a respite from the monotony of their work and a somewhat fun activity (people love holding or working with things in their hands). It was also much more approachable than other methods at the time.
In order to procrastinate from doing tasks that I don’t want to start I decided to read a couple chapters to refresh my lizard brain. This opening piece could have been written by myself, as it is in part my justification for not just using card sorting at the time, but what piqued my interest in user/customer centered in the first place.
How did I find my way to card sorting?
I was designing the information architecture for a large government website. The navigation categories had evolved over time and weren’t labeled clearly, so people had a lot of trouble finding even basic information. I now recognize this as a common problem, but at the time I just felt overwhelmed. The fact that this was a government site, and so contained essential information, added pressure—if potential users couldn’t find the information they needed, it would be my fault.
I had been tasked with reorganizing and relabeling the main groups of content on the home page and second-level pages. I had some ideas for how the content could be organized, based mainly on my own intuition. But how could I be sure that the categories that made sense to me would also make sense to someone else? What’s more, the team I was working with had been developing the website from the beginning. They weren’t about to restructure it just because the new kid thought something made sense—they wanted “evidence” that my intuitions were correct. Whatever I came up with, I’d have to be able to back it up.
Donna Spencer
By way of a definition …
Card sorting is one of a family of user research techniques designed to give you insight into how people think. Card sorting is best understood not as a collaborative method for creating navigation, but rather as a tool that helps us understand the people we are designing for.
IA: 撰寫文件的目的
撰寫系統功能或資料的架構的過程是一種創意—也就是我們在設計系統的同時也要設計一份可以說明系統的文件的這種創意。
透過文件的撰寫,我們會更了解整個系統設計的概念。當我們依照所撰寫的系統文件而開發出一個比較明確的系統版本時,我們也會發現如何來改善它。
由於IA本質上是一件相當抽象的工作,透過產出的東西才能讓它明確。撰寫文件是促進了解、進而教育以及推銷這個設計工作的關鍵。因此,我們所產出的東西就很重要了。
在現實的業務角度上,抽象代表:
- 沒有用
- 不能應用
- 難以理解
- 不能出售
An Information Architecture Process
I found this process amongst a category of old files – it dates from about 2002 when I was working with librarians to rearchitect various corporate web systems at the time. I’m sure I must have written this outline as a way to communicate next steps – we loved the waterfall process back then.
- Take all the content and features apart (analysis)
- Then put it all back together again (synthesis)
Analysis
- Create a complete listing of all content: Forget how content is produced, Political structures
- From the content audit, identify broad types of content
- Create core content attributes
- All content is intended:
- For someone (an audience)
- Who is trying to do something (a task)
- Identify intrinsic attributes of each content type
- Start with some simple questions:
- What is it? (White paper? Product review?)
- Who made it? (Author)
- When was it made? (Date Published)
- Where was it made? (Location/Company Published)
- What is it about?
- What type of media?
- All content is intended:
- Subject Attributes
- All content has a subject
- Subjects exist independent of content
- Subject attributes are highly specific to that subject
- Attribute Relevance
- Prioritization based on persona(s)
Synthesis
- Taxonomy
- Look for commonalities among attributes
- Group like attributes into categories
- Organize categories into hierarchies
- Primary and Secondary Structures
- Multiple overlapping taxonomies are very common
- Prioritize taxonomies by relevance
- Make less relevant taxonomies secondary
- Final Relevance (to target) and labeling
- Verify with testing
資訊架構與資訊設計的區別
這兩個概念有所不同,“資訊架構(IA)”主要與“認知”有關,即:人們如何處理資訊、如何分析不同資訊之間的關係;而“資訊設計(ID)”則與“感知”有關,即:人們如何將他們看到的和聽到的東西轉化為知識。
這兩種方式都需要不同的技能。“資訊架構師”來自各個領域,但我感覺其中大部分有語言學背景;而“資訊設計師”通常指向視覺藝術,因此,大部分資訊設計師來自同一個領域:平面設計。
“資訊架構”屬於抽象概念,它主要針對人腦中的資訊結構,而不是紙上或螢幕上的;而“資訊設計”則非常的具體,資訊設計師在設計過程中考慮的重點是顏色和基本形狀等具體資訊。
Translated from :
Differences between Information Architecture and Information Design
Between the two names we have different concerns. Information architecture (IA) is primarily about cognition, how people process information and construe relationships between different pieces of information. Information design is primarily about perception, how people translate what they see and hear into knowledge.
Both require different skills. Information architects come from a variety of backgrounds, but I sense that a majority of them display an orientation toward language. Information designers, on the other hand, tend to be oriented toward the visual arts. As a result, the majority of information designers come from exactly one discipline: graphic design.
Information architecture belongs to the realm of the abstract, concerning itself more with the structures in the mind than the structures on the page or screen. Information design, however, couldn’t be more concrete, with considerations such as color and shape fundamental to the information designer’s process.
Which I picked up many years ago from Jesse James Garrett.
Mobile Information Architecture: 4 different models
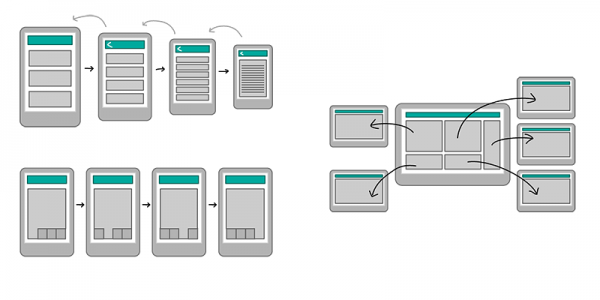
Mobile devices have their own set of Information Architecture patterns, too. While the structure of a responsive site may follow more “standard” patterns, native apps, for example, often employ navigational structures that are tab-based. Again, there’s no “right” way to architect a mobile site or application. Instead, let’s take a look at some of the most popular patterns: Hierarchy, Hub & spoke, Nested doll, Tabbed view, Bento box and Filtered view.
Designing for Mobile, Part 1: Information Architecture. Via Small Surfaces
Explaining Information Architecture
Principles of Successful Navigation
Navigation that works should:
- Be easily learned
- Remain consistent
- Provide feedback
- Appear in context
- Support users’ goals and behaviors
- Offer alternatives
- Require an economy of action and time
- Provide clear visual messages
- Use clear and understandable labels
- Be appropriate to the site’s purpose
Bullet points provided by Jennifer Fleming’s old but still relevant Web Navigation: Designing the User Experience (1998). I wore that book out reading and rereading on the bus ride to my main gig then.
An Interview with Jesse James Garrett
It’s unfortunate but not unexpected that the interview is viewable only in Windows Media (DevSource is basically a Microsoft mouthpiece), so if you are using a Mac don’t expect too much in terms of quality. It took me a few tries to get it to play and a few more to get through it. It’s still worth it.
“Jesse James Garrett is the “notorious” father of AJAX. You may not also realize that he’s also a writer, interface developer and designer, information architect, and experience strategist. He co-founded Adaptive Path in 2001, where he is now Director of User Experience Strategy. Garrett is the author of the popular book, The Elements of User Experience, and other groundbreaking works, and co-founder of the Information Architecture Institute.”
An Interview with Jesse James Garrett, the “father of ajax”
Does information need architects?
More on the “species”:
“… it was surprisingly hard to find someone willing to call herself an information architect. “I don’t like to call myself that because … ” was a common phrase used as people introduced themselves. Similarly, the question of the precise definition of information architecture was frequently raised and almost as frequently skirted. This is surprising at a conference whose attendance is booming and in a profession the value of which is clear and clearly increasing.
Nevertheless, the dividing line among information architects is real. One group tends more toward control and using expertise to create a structure that should work the same way for every user. The other tends more toward flexibility and enabling user interaction to determine the structure of the site and the content of the answers.”
Read the full article.
The Information Architect Species
A lighter look at what disciplines those who practice IA might have practiced before or in addition to becoming IA’s.
“Given that IA as a profession is really only about 10yrs old (or at least, that’s the figure I hear bandied about), it makes sense that *most* IAs have a ‘past life’ of one kind or another. This has got me to thinking that there are probably about six different species of Information Architect, based on the kind of professional past life they’ve had (nor not).”
Read The six species of Information Architect at disambiguity
Four Modes of Seeking Information and How to Design for Them
Information-seeking behavior varies from situation to situation. Donna Mauer explores different ways in which users look for information and offers tactics for accommodating them.
Four Modes of Seeking Information and How to Design for Them – Boxes and Arrows
(Garret IA) 描述信息结构和交互设计的图示词汇表
I don’t think I have linked to the Chinese version of JJ Garrett’s Visual Vocabulary in the past. Though not set in Big 5 this could use some promotion as more Taiwanese designers start to understand and utilize the fundamental building blocks of building web sites that IA is. Using a shared visual vocabulary such as this saves us time and effort.
“图表是网络应用开发团队(Web development teams)在沟通信息架构和交互设计方面最基本的工具。本文所讨论的是使用图表来描述系统时所要考虑的事宜、信息架构和用户交互设计时使用这些基本元素的要点,并且介绍这些元素的使用方法。”
Jesse James Garrett: Visual Vocabulary for Information Architecture (Chinese)
Christmas Books on IA and Teams
I received a number of books for Christmas and I thought I would share a couple. I’m not one for book reviews but I’m sure some of the thoughts contained in these books will make it into later posts. I have hard time getting through my library of texts pertaining to Information Architecture, Experience Design, and the like. You have to be pretty dedicated to read from the beginning to end George Lakoff’s “Women, Fire, and Dangerous Things” or even Sorting Things Out
. These books just seem very dry. I have high hopes for Peter Morville’s Ambient Findability
which at first glance looks well written with an easily digestible format similar to Steve Krug’s “Don’t Make Me Think”
. Amazon describes the book better than I will as follows:
“How do you find your way in an age of information overload? How can you filter streams of complex information to pull out only what you want? Why does it matter how information is structured when Google seems to magically bring up the right answer to your questions? What does it mean to be “findable” in this day and age? This eye-opening new book examines the convergence of information and connectivity. Written by Peter Morville, author of the groundbreaking Information Architecture for the World Wide Web, the book defines our current age as a state of unlimited findability. In other words, anyone can find anything at any time. Complete navigability.”
The other book, Ricardo Semier’s “Maverick” might also prove to be a good read and it’s a topic I’m quite interested in – how to transform your workplace. Here’s a long passage from the end of the book:
“To survive in modern times, a company must have an organizational structure that accepts change as its basic premise, lets tribal customs thrive, and fosters a power that is derived from respect, not rules. In other words, the successful companies will be the ones that put quality of life first. Do this and the rest – quality of product, productivity of workers, profits for all – will follow. At Semco we did away with strictures that dictate the “hows” and created fertile soil for differences. We gave people an opportunity to test, question, and disagree. We let them determine their own futures. We let them come and go as they wanted, work at home if they wished, set their own salaries, choose their own bosses. We let them change their minds and ours, prove us wrong when we are wrong, make us humbler. Such a system relishes change, which is the only antidote to the corporate brainwashing that has consigned giant businesses with brilliant pasts to uncertain futures.”
Ambient Findability : What We Find Changes Who We Become and Maverick : The Success Story Behind the World’s Most Unusual Workplace
IA 2.0 at UXMatters
“The typical information architect thinks about structure – how one item in a group relates to all the other items in the group and how that group relates to all other groups. In the early days of information architecture (IA), groups and their related items tended to be well defined. For example, in the heyday of e-commerce, an information architect translated a product catalog into a storefront on the Web. Today, these problems seem old hat.”
“Beyond the technology, however, Web 2.0 brings with it a shift in mind-set. Today, people trust online content that individuals publish more than they did in the early days of the Web. Many people now willingly share information—like photographs or favorite Web sites or wish lists—freely on the Web and see sharing this information as beneficial.”
I dislike the whole web 2.0 labeling and hype and his use of IA 2.0 seems unnecessary but this article does bring to light the fact that there is allot to think about in how IA responds to new mindsets and technologies. I wonder how long it will take for the concepts and practices introduced via sites like Flickr to percolate down through to those who control budgets and initiate projects in Taiwan. Somehow I think we haven’t hit IA 0.5 yet.
This article is from UXMatters, a new publication for user experience professionals.
Read: Information Architecture 2.0
Information Architecture Out of Fashion?
Before I took an all too brief detour into sound and tangible interfaces I was really quite interested in information architecture – I spoke allot about the topic here in the hinterlands of Taiwan and tried to put into practice all the theory I learned. At that time their was a tremendous amount of discussion surrounding IA and a vast library of literature. Lately having regained my interest and with some work coming I have set out to absorb any or all the latest thinking on the subject. But browsing all my old IA haunts have brought up little in the way of discussion, at least when compared to a few years ago. All I found were news announcements for various IA summits. Has the online discussion stopped? Have information architects all been forced to become business development managers or gone back to being librarians? Have sites that popularized social tagging made the information architect obsolete?
I’ll keep wading through all the bs hype about web 2.0 and ajax in the hope that I find something new to read.
Shirky: Ontology is Overrated
“I want to convince you that many of the ways we’re attempting to apply categorization to the electronic world are actually a bad fit, because we’ve adopted habits of mind that are left over from earlier strategies.
I also want to convince you that what we’re seeing when we see the Web is actually a radical break with previous categorization strategies, rather than an extension of them. The second part of the talk is more speculative, because it is often the case that old systems get broken before people know what’s going to take their place. (Anyone watching the music industry can see this at work today.) That’s what I think is happening with categorization.”
Read: Shirky: Ontology is Overrated — Categories, Links, and Tags
Explain “Information Architecture” in 10 words or less
Jason Fried of 37signals is making an interesting point, there is no common concise answer to what the terms means.
Three years ago I threw together this definition from various sources:
Information architecture (IA) is primarily about cognition – how people process information and construe relationships between different pieces of information. Information design is primarily about perception – how people translate what they see and hear into knowledge.
These days I tend to believe “I don’t know, but I’m sure the information architect does” and “Information Architect (noun): title invented by web designers desiring a software engineer’s salary.”
Read: An exercise in clarity: Explain “Information Architecture” in 10 words or less
Tagging for Fun and Finding
“We all grew up knowing about tags. We had tags in our clothes, we had them on our holiday presents, we played a game called tag, and some even used spray cans to tag their turf. All of these uses of tag have different meanings, but unless we understand the context and/or the person using the word tag we do not know what they mean. This can be a problem with tagging on the web, but like everything else there are two sides to the story and there are some great benefits from tagging, if it is done well.”
Read the article
The Death of Hierarchical Folders
This is a must read for anyone interested in information architecture.
“Hierarchical Folders have dominated info organization since they first appeared over 40 years ago. But in industry after industry, a strange thing is happening: hierarchy is under severe attack, and even dying out.”
Read: Google’s War on Hierarchy, and the Death of Hierarchical Folders. Found via Webword.
IA as a competitive advantage
“America’s entertainment industry is committing slow, spectacular suicide, while one of Europe’s biggest broadcasters – the BBC – is rushing headlong to the future, embracing innovation rather than fighting it.”
“The BBC is indeed quietly getting way ahead of most other media companies.
I often talk about IA as a competitive advantage: the BBC gets that. (I shouldn’t define IA this broadly, but hey). They have consistent URI’s for every program ever made (working on it at least), they have API’s in the new BBC Backstage, they embrace RSS and let users play with their data. In other words: they architect their information with an eye towards the future. Long term metadata. Good URI’s. Open to users.
The big advantage the BBC has had is that it’s attitude towards information hasn’t been lead by vendor pitches, but by passionate and talented people for years. You can’t just buy that, or expect to catch up with that in a year or two. That’s IA as a competitive advantage.”
From IA as a competitive advantage on Wired News: The Beeb Shall Inherit the Earth
A Primer on Faceted Navigation and Guided Navigation
“What is faceted navigation? It’s a way to browse information, or to refine long lists of search results, along multiple dimensions, aka facets. These are orthogonal lenses through which to view the world. For example, I might search for an expert by facets like name, project, company, or dates and more likely, by some combination of those facets, selected in any sequence.”
Go to the article
Mapping an Information Space (ba)
“To successfully communicate the characteristics of an information space, I needed an approach for creating easily understood diagrams. To be useful to my audience, the diagrams must communicate the “big picture”? of the website to stakeholders, while providing enough detail to be useful for the development team.”
Read:Site Diagrams: Mapping an Information Space
Information Architecture Heuristics (Rosenfeld)
“Just finished a brief heuristic evaluation of a client site, basing part of my feedback on a set of questions that I find quite useful for just about every IA-related project. Every information architect should always have a set of favorite questions in their back pocket; they really do come in handy.”
Card Sorting: How Many Users to Test (Jacob Neilson)
From Jakob Nielsen’s – Alertbox comes: “Testing ever-more users in card sorting has diminishing returns, but you should still use three times more participants than you would in traditional usability tests.” Courtesy InfoDesign: Understanding by Design
A definitive guide to cart sorting
“Card sorting is a technique that many information architects (and related professionals.) use as an input to the structure of a site or product. With so many of us using the technique, why would we need to write an article on it?
While card sorting is described in a few texts and a number of sites, most descriptions are brief. There is not a definitive article that describes the technique and its variants and explains the issues to watch out for. Given the number of questions posted to discussion groups, and discussions we have had at conferences, we thought it was time to get all of the issues in one place.
This article provides a detailed description of the basic technique, with some focus on using the technique for more complex site.” @ Boxes and Arrows.
Six Steps to Better Interviews and Simplified Task Analysis (Adaptive Path article)
From Adaptive Path comes another fine article “Six Steps to Better Interviews and Simplified Task Analysis”.
“I spend a lot of time helping clients conduct task analysis to form mental-model diagrams. When teams first start analyzing the interview transcripts they
How to Make a Faceted Classification and Put It On the Web
via IASlash
“This paper will attempt to bridge the gap by giving procedures and advice on all the steps involved in making a faceted classification and putting it on the web. Web people will benefit by having a rigorous seven-step process to follow for creating faceted classifications, and librarians will benefit by understanding how to store such a classification on a computer and make it available on the web. The paper is meant for both webmasters and information architects who do not know a lot about library and information science, and librarians who do not know a lot about building databases and web sites. The classifications are meant for small or medium-sized sets of things, meant to go on public or private web sites, when there is a need to organize items for which no existing classification will do. It is certainly not the intent of this paper to show how to build another universal classification, nor to describe how a library that uses a faceted classification scheme can put their catalogue online.
There are four main sections to this paper: when to make a faceted classification, how to make one, how to store it on a computer, and how to make it work on the web. I will concentrate on the middle two sections. The question of when to use facets is not particularly difficult (leaving aside general questions about the purpose and usefulness of classifications). Detailed advice on the design and implementation of a good web site is beyond the scope of this paper and requires a companion web site, with examples, to be best understood (but see Nielsen (2000) for excellent advice). In the final section I offer some guidelines on what to consider when putting facets on the web, but the discussion is not lengthy. The two middle sections about how to make and store a faceted classification receive a much fuller treatment.”
Read: How to Make a Faceted Classification and Put It On the Web